



Дата публикации: .
Главный вывод 2026 года: чтобы адаптировать пользовательскую документацию для ИИ, её нужно превратить из пассивного справочника в активный слой данных для генеративных ИИ-систем. Качество ответов корпоративных чат-ботов, построенных на RAG (Retrieval-Augmented Generation), определяется не моделью, а корпусом знаний. Неструктурированная, противоречивая или устаревшая справочная система — главная причина галлюцинаций, которые в B2B-сценариях оборачиваются прямыми финансовыми потерями: по оценкам отраслевых аналитиков, перерасход бюджета на ИИ-проекты связан именно с качеством исходных данных. Эта статья — обзор для технических писателей, AI-инженеров и менеджеров, которые хотят узнать, как подготовить руководство пользователя для нейросетей и превратить его в конкурентное преимущество.
Контекстная инфраструктура: определение, архитектура и место в IT-ландшафте
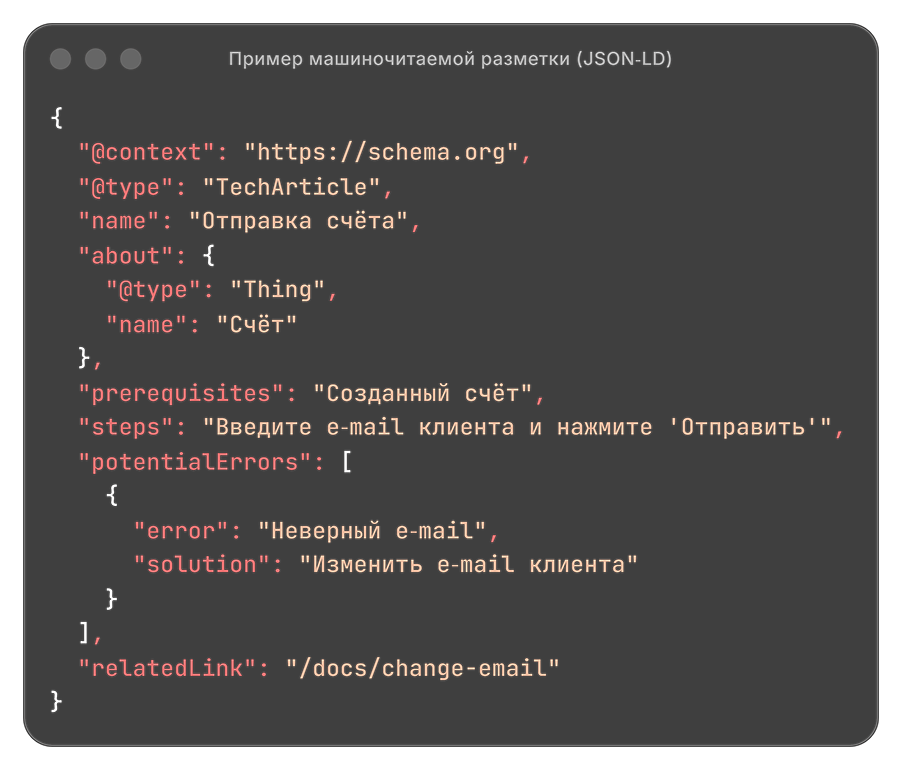
Контекстная инфраструктура — это совокупность методов, форматов и инструментов, обеспечивающих семантическую связность, однозначность и машиночитаемость документации на всех уровнях: от исходного текста до векторизованных представлений и графов знаний. В отличие от традиционной иерархической справки, она строится как семантический граф, где каждый раздел — это узел с метаданными (тип, версия продукта, целевая аудитория, предусловия, ошибки), а связи между узлами явно специфицированы (см. стандарт JSON‑LD и схемы типа Schema.org).
В 2026 году справочная документация официально признана четвёртым столпом IT-инфраструктуры (наряду с кодом, данными и CI/CD). Согласно данным отраслевых аналитиков, 68% компаний из списка Fortune 500 уже выделяют отдельный бюджет на "AI‑readiness контента", однако лишь 22% могут похвастаться зрелыми практиками. В России, по оценкам профильных экспертов, около 80% организаций признают, что их база знаний не пригодна для машинной обработки — разрыв между ожиданиями и реальностью остаётся главным барьером на пути к эффективному использованию ИИ.
Почему классические подходы нефункциональны для LLM: системный анализ
Традиционная документация ориентирована на последовательное чтение человеком: разделы "Как сделать X" изолированы, примеры даны без контекста, а терминология может варьироваться. Для LLM, которая не обладает внутренней памятью о прочитанном вне окна контекста, такой материал превращается в набор слабо связанных фактов. Модель не в состоянии вывести имплицитные связи, что приводит к трём классам ошибок:
- Галлюцинации — когда модель "додумывает" отсутствующую информацию.
- Противоречия — если в разных местах описана одна операция по-разному, модель выбирает случайную версию.
- Потеря контекста — когда для ответа требуются сведения из нескольких разделов, а ретривер не может их собрать из-за плохой структуры.
Сравним подходы по ключевым параметрам:
| Параметр | Традиционная документация | Контекстная инфраструктура |
|---|---|---|
| Целевой потребитель | Человек (чтение, визуальный поиск) | LLM / ИИ-агент (извлечение, логический вывод) |
| Структура | Иерархическая (разделы → подразделы) | Семантический граф + топики с метаданными (версия, тип, зависимости) |
| Форматы | HTML, PDF, Markdown (свободный текст) | Markdown + фронт-материя, OpenAPI/AsyncAPI, JSON‑LD, RDF, структурированные примеры |
| Поиск и извлечение | Ключевые слова, полнотекстовый поиск (BM25) | Гибридный поиск (BM25 + плотные векторы), reranking, доступ к графу знаний |
| Требования к контенту | Уникальность, ключевые слова для SEO | Однозначность, консистентность, явные перекрёстные ссылки, машиночитаемая разметка |
| Метрики качества | Время поиска, удовлетворённость пользователя | Hit Rate@K, Mean Reciprocal Rank (MRR), точность ответов чат-бота, снижение галлюцинаций |
| Цикл обновления | Раз в квартал / по релизам | CI/CD с синхронизацией по коммитам в код (docs‑as‑code) |
Критическое отличие: LLM требует явной семантической связности. Например, если действие "подтвердить заказ" в одном месте называется "approve order", а в другом — "confirm order", модель может классифицировать их как разные операции. Для устранения этого внедряют глоссарии с URI и используют переменные (как в коде) вместо жёстко зашитых названий.

Как писать пользовательскую документацию для ВПК РФ в 2026 году?

Как стать экспертом по нейросетям в 2026 году: фундаментальные знания для технического писателя

Как понять, что пользовательская документация работает?

Перенос пользовательской документации на российские HAT: пошаговое руководство по миграции (2026)

Как создать ИИ-агента для аннотирования веб интерфейса?

Как пройти экспертизу Минцифры в 2026 году: инструкция по подготовке документации

Как создать ИИ-агента для пользовательской документации в 2026 году?

Как выбрать шрифт для пользовательской документации в 2026 году?

Как персонализировать пользовательскую документацию?

Пишем пользовательскую документацию по методу Стивена Кинга

Как сделать аннотации и подписи к скриншотам в MS Word в 2026 году?

Разработка документации для приборов и промышленного оборудования: особенности, инструменты, специальные приемы

Разработка документации для систем автоматизации производственных и бизнеc-процессов

Разработка пользовательской документации для бухгалтерского ПО и систем учета: особенности, инструменты, специальные приемы

Разработка пользовательской документации для ERP-систем: особенности, инструменты, специальные приемы

Разработка документации для САПР и BIM-систем: особенности, специальные приемы и инструменты

Как выбрать программу для написания пользовательской документации: SaaS или десктопное ПО?
Пользовательская документация как слой данных (data layer): архитектура, компоненты и лучшие практики
Слой данных для ИИ — это корпус, оптимизированный под RAG-пайплайн. Полноценный пайплайн включает:
- Сбор и очистка — извлечение контента из всех источников (репозитории, вики, тикеты поддержки). Инструменты: Unstructured, LlamaIndex (читает более 100 форматов).
- Структурирование и аннотация — добавление метаданных (тип топика, продукт, версия, цель, сложность). Используются схемы JSON‑LD или фронт-материя в Markdown.
- Чанкинг (разбивка) — оптимальный размер чанка для эмбеддингов (512–1024 токена) с перекрытием (10–15%) для сохранения контекста на границах. Стратегии: семантический (по предложениям) или фиксированный (по токенам).
- Векторизация — выбор модели эмбеддингов (например, E5-Mistral, Cohere Embed v3 или OpenAI text-embedding-3-large) с учётом домена (техническая лексика требует дообучения на корпусе кода и базы знаний).
- Индексация и поиск — гибридный подход (BM25 + плотные векторы) с последующим reranking (cross-encoder) для повышения точности. Популярные векторные базы: Pinecone, Weaviate, Milvus.
- Мониторинг и обратная связь — логирование всех запросов, использованных чанков и оценок пользователей для непрерывного улучшения.
Практические кейсы с цифрами:
- MongoDB переработала 70% своих руководств в семантически связанные топики с явными "связанными разделами" и внедрила валидатор дубликатов. После этого их внутренний AI-ассистент показал снижение ошибочных ответов на 62% (измерялось по метрике factual consistency на тестовом наборе из 500 вопросов).
- Google Cloud внедрил стандартизированные шаблоны для каждого типа документа (концепция, процедура, справочник) и добавил обязательную секцию "Prerequisites" и "Troubleshooting". Точность ответов Gemini на технические вопросы выросла на 45% (по тесту BIG‑Bench для QA).
- Яндекс (исследование 2025) сообщила, что переход на структурированные карточки для YandexGPT в поддержке сократил количество эскалаций (передач запроса или проблемы пользователя на более высокий уровень компетенции) операторам на 37%.
Скрытые сложности: системные риски и их митигация
1. Невидимость использования ИИ: аналитика нового типа
Стандартные веб-аналитики не фиксируют, как LLM "обходит" инструкции. Необходимо внедрение RAG-логирования: каждый запрос к чат-боту должен записывать, какие именно чанки были использованы, их ранжирование и итоговый ответ. Это позволяет выявить "белые пятна" (вопросы без релевантных чанков) и "шумы" (часто выбираемые, но нерелевантные чанки). Инструменты: Arize, Honeycomb для трассировки, а также open-source решение LlamaHub с настраиваемыми колбэками.
2. Синхронизация с частыми релизами и технический долг
Когда продукт обновляется еженедельно, справочная система должна обновляться в том же ритме. Решение — docs-as-code с CI/CD пайплайнами, где каждый pull request в код запускает проверку руководства пользователя: линтер (например, Vale) проверяет терминологию, а автоматические тесты сверяют примеры кода с актуальными API. Дополнительно внедряются метки валидности (valid_until) для каждого топика, и по истечении срока топик помечается как устаревший, а RAG-пайплайн его исключает.
3. Совокупная стоимость владения (TCO) и стратегия пилотирования
Переход на контекстную инфраструктуру требует инвестиций: переразметка 1000 страниц стоит от $20K до $100K в зависимости от сложности, плюс затраты на инфраструктуру векторизации и обучение команды. Однако для компаний с большим объёмом обращений в поддержку (более 10 000 тикетов в месяц) окупаемость наступает за 6–9 месяцев за счёт сокращения времени операторов. Рекомендуется гибридный подход:
- Выберите 5–10 самых частых запросов (по данным поддержки) и создайте для них идеальные ответы.
- Структурируйте соответствующие разделы справочника, добавьте метаданные и проиндексируйте.
- Подключите тестового чат-бота и измерьте улучшение качества (по метрикам точности и полноты) в течение 1 месяца.
- Только после подтверждения ROI масштабируйте на остальной контент.
4. Юридические и этические риски
При автоматической генерации ответов на основе базы знаний компания несёт ответственность за достоверность. Рекомендуется для критических сценариев использовать контент, написанный человеком, а также вести журнал всех ответов для аудита. В 2025 году ЕС опубликовал AI Act, где прописаны требования к прозрачности источников — информация должна быть снабжена прослеживаемыми ссылками на первоисточник.
Двунаправленная справочная система и стандартизация
В ближайшие 2–3 года мы увидим три ключевых тренда:
- Обратная связь от ИИ к документации — AI-агенты будут не только читать, но и предлагать обновления на основе обращений пользователей. Например, если чат-бот не может ответить на вопрос, он автоматически формирует заявку для техписа с указанием недостающих фактов. Компании вроде ServiceNow уже тестируют такие циклы.
- Стандартизация "AI-ready docs" — по аналогии с
llms.txtдля сайтов, ожидается появление спецификаций (например, W3C AI Knowledge Community разрабатывает стандарт для аннотации инструкций). К 2028 году, вероятно, возникнут сертификации (как DITA для компонентного руководства пользователя). - Интеграция с графами знаний предприятия — корпоративная база знаний будет связана с другими данными (код, тикеты, логи) в едином графе, что позволит ИИ отвечать на вопросы типа "Почему произошла ошибка X при версии Y?" с привлечением всех источников.
Практический чек-лист для технического писателя и AI-инженера
- Аудит: проведите инвентаризацию всего контента. Оцените дублирование (поможет инструмент Duplicati или скрипты на основе косинусного сходства).
- Терминология: создайте единый глоссарий (в формате YAML/JSON) и пропишите правила его использования (например,
термин: "название"— всегда писать именно так). Внедрите линтер для проверки. - Разметка: дополните каждый топик метаданными:
concept, procedure, reference, troubleshooting,product_version,prerequisites,related_topics(URI). Используйте JSON-LD или фронт-материю. - Пилотный набор: выберите 20–30 топиков, которые покрывают 80% запросов в поддержку. Подготовьте их по новым стандартам.
- Техническая реализация: настройте пайплайн индексации (например, с использованием LangChain + Elasticsearch с векторами или Qdrant).
- Оценка: соберите бенчмарк из 100–200 вопросов с эталонными ответами. Вычисляйте процент вопросов, где правильный чанк попал в топ‑5 (Hit Rate@5) и MRR. Целевые значения для технической документации: Hit Rate@5 > 0.85, MRR > 0.75.
- Мониторинг: внедрите сбор логов RAG с обязательным полем
retrieved_chunksиanswer_helpful(оценка пользователя). Строить дашборды (Grafana, Kibana) для отслеживания динамики. - Обучение команды: проведите тренинги для техписов по принципам семантической разметки, работы с RAG-метриками и основам векторизации.
Если вы только начинаете — не стремитесь охватить всё сразу. Начните с аудита: возьмите 10 типовых вопросов поддержки и проверьте, сколько из них можно полностью закрыть существующим справочником (без помощи человека). Это даст вам базу для приоритезации.
Заключение
Пользовательская документация в эпоху генеративного ИИ — это стратегический актив, требующий системного подхода к архитектуре, метаданным и процессам. Компании, которые игнорируют переход к контекстной инфраструктуре, столкнутся с растущим разрывом между ожиданиями пользователей от AI-агентов и реальным качеством сервиса. Однако полная трансформация не обязана быть дорогой и рискованной: пилотный подход, измеримые метрики и итеративное улучшение позволят получить быстрые результаты. Начните с 20% контента, который даёт 80% бизнес-ценности, и уже через квартал вы увидите снижение нагрузки на поддержку, рост доверия клиентов и чёткое понимание, как двигаться дальше. В 2026 году это не просто тренд — это конкурентное преимущество, которое окупается в течение года.