



Дата публикации: .
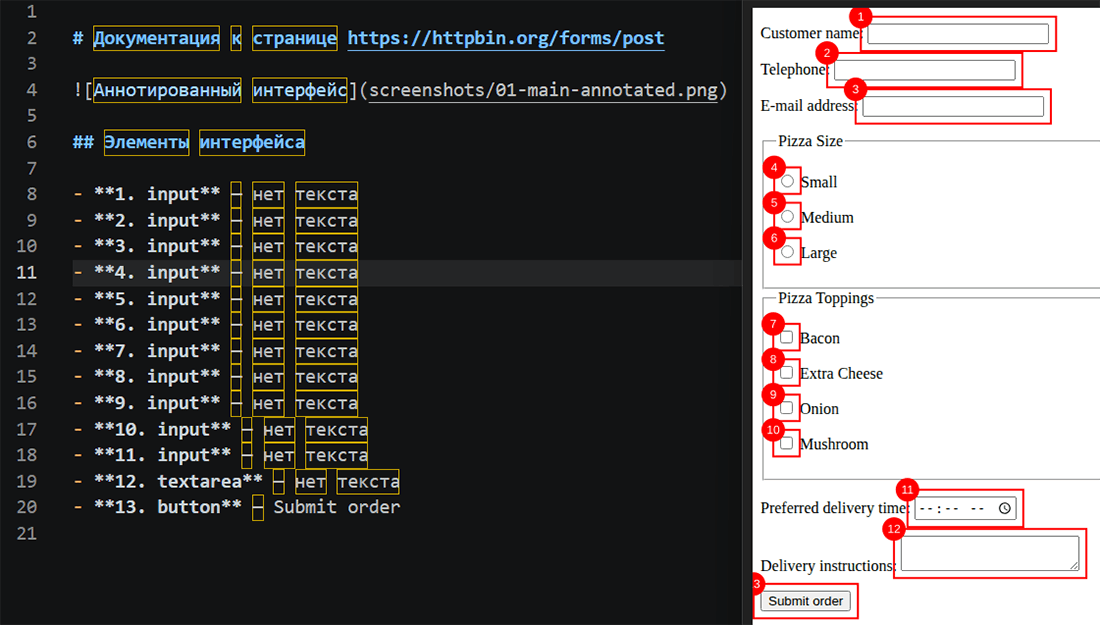
В этом руководстве вы узнаете, как создать агента, который автоматически аннотирует веб-страницу и генерирует документацию в формате Markdown. Агент будет запускаться прямо в облаке с помощью GitHub Actions — никаких локальных серверов, сложной настройки или платных сервисов. Вы просто даёте ему ссылку на страницу (в данном примере показана страница https://httpbin.org/forms/post), и получаете архив с аннотированным скриншотом и описанием интерфейса в формате Markdown.
Структура проекта будет выглядеть так:
ai-docs-agent/
├── .github/
│ └── workflows/
│ ├── generate-docs.yml ← основной workflow
│ └── generate-lock.yml ← вспомогательный workflow (опционально)
├── scripts/
│ ├── capture-and-document.js ← главный скрипт агента
│ └── vision-caption.js ← заглушка (можно оставить пустой)
├── templates/
│ └── doc-template.md ← Handlebars-шаблон выходного документа
├── package.json ← зависимости и метаданные проекта
├── .gitignore ← исключает node_modules/ (и output/ при желании)
└── README.md ← исходное описание (позже заменится сгенерированным)
Ссылка на проект.
Шаг 1: Создаём новый репозиторий на GitHub
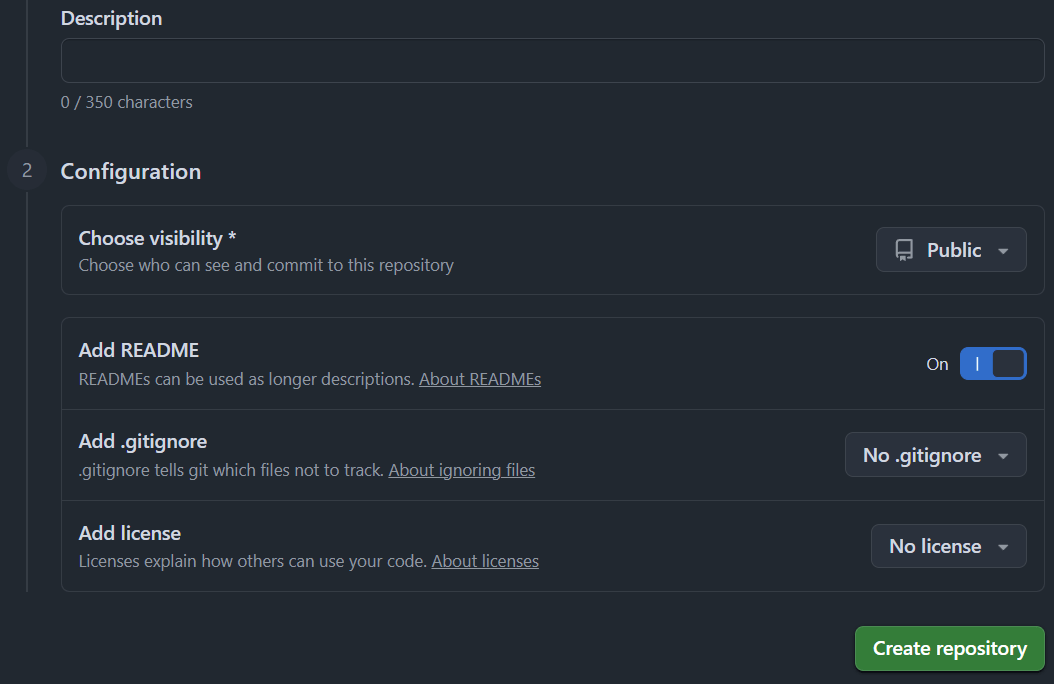
- Зайдите в свой аккаунт на GitHub и нажмите кнопку New (или перейдите по адресу github.com/new).
- В поле Repository name введите
ai-docs-agent(или любое другое название). - В Choose visibility выберите Public — это важно для бесплатного использования GitHub Actions: в приватных репозиториях есть лимиты, а публичные работают без ограничений.
- Включите Add README — позже мы заменим его сгенерированной документацией.
- Нажмите Create repository.
Шаг 2: Готовим структуру проекта
Нам понадобятся три ключевых файла:
package.json(список зависимостей);scripts/capture-and-document.js(основной скрипт);.github/workflows/generate-docs.yml(конфигурация GitHub Actions).
Описанный стек — не единственный способ решить задачу. Полезно знать о вариантах, чтобы выбрать подходящий под свои ограничения.
- Puppeteer вместо Playwright. API практически идентичен, но Playwright поддерживает кросс-браузерность (Chromium, Firefox, WebKit) и даёт более полные отчёты об ошибках. Если вы уже используете Puppeteer в проекте, миграция скрипта займёт не больше часа.
- Готовые облачные сервисы (например, Urlbox, ScreenshotAPI). Не требуют настройки CI/CD, умеют ждать загрузки контента и обходить базовую бот-защиту. Минус — стоимость запросов и невозможность накладывать произвольные SVG-аннотации без дополнительной обработки.
- Расширения для браузера. Если нужно документировать страницы, доступные только после входа в корпоративную учётную запись, проще написать браузерное расширение, которое делает скриншот из контекста активной сессии пользователя. Такой подход не требует настройки headless-окружения, но теряет главное преимущество — полностью автоматический запуск в облаке.
Каждый вариант смещает баланс между простотой настройки, стоимостью эксплуатации и гибкостью настройки аннотаций. Предложенный в статье стек оптимален, если вы готовы потратить час на начальную конфигурацию и цените независимость от сторонних вендоров.
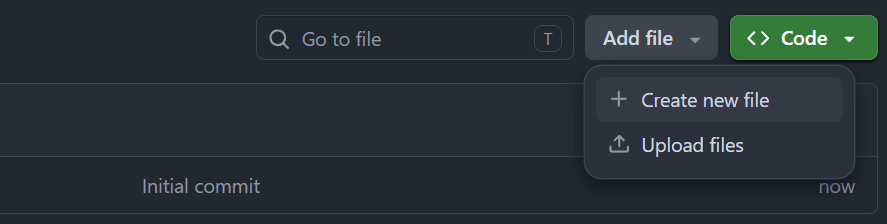
В меню репозитория нажмите кнопку Add file и в выпадающем меню нажмите Create new file:
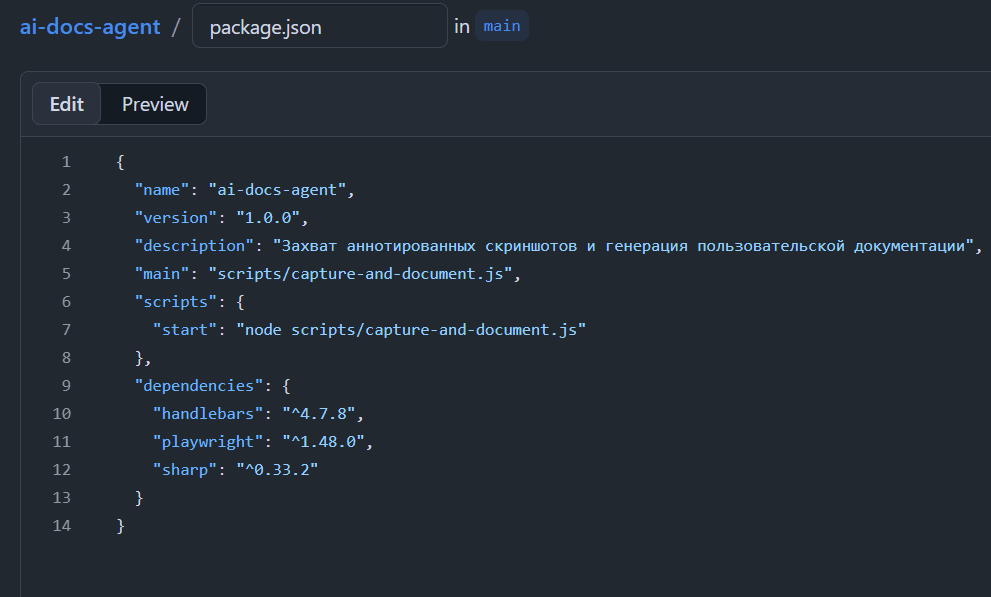
Добавим package.json в корень репозитория. В нём будут указаны три библиотеки:
playwrightдля управления браузером;sharpдля наложения аннотаций;handlebarsдля шаблонов документации.
Код файла package.json:
{
"name": "ai-docs-agent",
"version": "1.0.0",
"private": true,
"dependencies": {
"handlebars": "^4.7.8",
"playwright": "^1.45.0",
"sharp": "^0.33.2"
}
}
Нажмите зеленую кнопку Commit changes:
Во всплывающем окне снова нажмите Commit changes, чтобы сохранить изменения.
Также создайте файл .gitignore с содержимым:
node_modules/output/Шаг 3: Добавляем основной скрипт
Создайте папку scripts, а в ней файл capture-and-document.js.
Для этого в репозитории снова нажмите кнопку Add file - Create new file и в поле для ввода названия файла впишите scripts/capture-and-document.js. GitHub сам отформатирует это следующим образом:
Файл capture-and-document.js — это сердце нашего агента. Скрипт принимает URL из аргументов командной строки, открывает страницу в headless-браузере Chromium, находит элементы интерфейса (кнопки, поля ввода, ссылки, заголовки), отбирает первые 15 и рисует на скриншоте красные прямоугольники с номерами.
Код файла находится на этой странице (нужна регистрация на GitHub).
Этот скрипт самодостаточен и может работать локально после установки зависимостей. Но мы пойдём дальше и обернём его в GitHub Actions, чтобы запускать одним кликом.
Мы аннотируем страницу с 15 элементами, чтобы не превысить лимит токенов. О токенах и особенностях Github Actions при создании агента мы писали в статье Как создать ИИ-агента для пользовательской документации в 2026 году?. В ней вы найдете решение проблем, которые могут возникнуть во время работы агента. Чаще всего они связаны с системой безопасности Github. Также рекомендуем ознакомиться с ограничениями Github Actions.
Шаг 4: Настраиваем GitHub Actions
Теперь создадим файл рабочего процесса, который будет запускать наш скрипт при ручном триггере. В корне репозитория создайте папку .github/workflows (кнопка Add file - Create new file), а в ней — файл generate-docs.yml. Для этого впишите в поле названия файла workflows/generate-docs.yml:
Добавьте код:
name: AI Docs Agent
on:
workflow_dispatch:
inputs:
url:
description: 'Введите ссылку:'
required: true
default: ''
jobs:
generate:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Setup Node
uses: actions/setup-node@v4
with:
node-version: 20
- name: Install dependencies
run: npm install && npx playwright install --with-deps chromium
- name: Run documentation agent
run: node scripts/capture-and-document.js "${{ github.event.inputs.url }}"
- name: Upload generated docs
uses: actions/upload-artifact@v4
with:
name: user-documentation
path: output/
Этот workflow делает всё автоматически: скачивает код, ставит Node.js и Playwright, запускает скрипт с переданным URL и упаковывает результат в артефакт.
Шаг 5: Первый запуск
Перейдите на вкладку Actions вашего репозитория.
В левом меню нажмите AI Docs Agent, затем — кнопку Run workflow справа. Появится поле Введите ссылку: для ввода URL. Введите адрес любой страницы, например https://httpbin.org/forms/post, и нажмите зелёную кнопку Run workflow.
Выполнение занимает около 30–90 секунд. За это время GitHub Actions развернёт виртуальную машину, установит всё необходимое и запустит скрипт. Вы увидите логи в реальном времени: сообщения об открытии страницы, количестве найденных элементов и успешном сохранении скриншотов.
Когда процесс завершится (появится зелёная галочка), в меню слева нажмите пункт Summary:
Внизу страницы выполнения появится секция Artifacts. Нажмите в правом нижнем углу кнопку Download user-documentation, чтобы скачать ZIP-архив.
Внутри архива вы найдете папку output/ с файлами:
screenshots/01-main.png— чистый скриншот страницы.screenshots/01-main-annotated.png— скриншот с аннотациями (красные рамки с номерами).README.md— автоматически сгенерированная документация.
Ограничения: когда агент не справляется
Описанный подход универсален, но у него есть границы применимости, которые важно учитывать до запуска в рабочем проекте.
- Одностраничные приложения (SPA) с ленивой загрузкой. Агент ждёт события
networkidle, но не взаимодействует с интерфейсом: не скроллит, не кликает. Если контент подгружается динамически при прокрутке или после действий пользователя, он останется невидимым и не попадёт в скриншот. - Страницы за авторизацией. Скрипт не умеет вводить логин и пароль. Если страница требует аутентификации, агент зафиксирует только форму входа. Обходное решение — передавать куки или токен через переменные окружения, но это требует доработки кода.
- CAPTCHA и бот-защита. Некоторые сайты блокируют headless-браузеры. В таких случаях скрипт упадёт с ошибкой загрузки страницы без внятного сообщения.
- Очень длинные страницы. Фиксированный viewport 1280×720 пикселей обрезает всё, что не поместилось. Для захвата полной страницы пришлось бы делать несколько скриншотов с прокруткой и склеивать их, что резко усложняет логику аннотаций.
- Нетипичная вёрстка. Если элементы интерфейса построены на Canvas, WebGL или внутри Shadow DOM, стандартные CSS-селекторы их не увидят. Потребуется иной подход к выделению областей.
Во всех перечисленных случаях результат либо будет неполным, либо агенту потребуется существенная доработка под конкретный сайт.
Шаг 6: Адаптируйте под свои задачи
Агент готов к использованию, но его поведение легко менять. Вот несколько идей для кастомизации:
- Измените набор селекторов. В скрипте
capture-and-document.jsнайдите массивSIGNIFICANT_SELECTORSи добавьте нужные вам HTML-теги, напримерimgилиtable. Это позволит аннотировать другие типы элементов. - Увеличьте количество аннотаций. Замените
elements.slice(0, 15)(файлscripts/capture-and-document.js) на другое число — хоть 50, если страница очень насыщенная. Мы выбрали первые 15, чтобы не превысить лимит, доступный на бесплатном тарифе. - Настройте шаблон документации. В коде есть Handlebars-шаблон в виде строки. Вы можете вынести его в отдельный файл
templates/doc-template.mdи усложнить структуру документа: добавить раздел "Назначение страницы", "Распространённые сценарии" или "Советы".
Заключение
Мы создали агента, который автоматизирует рутинную часть работы технического писателя: делает аннотированный скриншот и формирует заготовку пользовательской документации. Весь код остаётся в вашем репозитории, и вы полностью контролируете логику его работы. Автоматическое аннотирование интерфейсов — лишь первый шаг. В ближайшее время можно ожидать несколько усиливающих технологий, которые логично встраивать в подобных агентов.
- Генерация текстовых описаний через LLM. Вместо сухого перечисления тегов и текстов элементный список можно отправлять в языковую модель (Gemini, GPT, Claude) с промптом "Составь руководство пользователя для этой страницы". Локально работающие модели (Ollama, LM Studio) делают это без утечки данных и дополнительных затрат.
- Распознавание иконок и изображений. Сейчас кнопка без текста получит описание "button — нет текста". Модели компьютерного зрения (BLIP, CLIP) способны заменить его на "кнопка поиска (иконка лупы)" — это резко повышает полезность документации.
- Сравнение версий интерфейса. Запуская агента на двух версиях продукта и вычитая один скриншот из другого, можно автоматически подсвечивать изменения в UI. Для техписателей это означает, что чейнджлог интерфейса можно генерировать, а не писать.
- Интеграция с Docs-as-Code. Выходной Markdown легко встраивается в пайплайны сборки документации (Hugo, Docusaurus, MkDocs). При коммите в репозиторий продукта агент может автоматически обновлять скриншоты в справочном центре без участия человека. Об актуальности подхода Docs-as-Code мы писали в статье Нужен ли Docs as Code для разработки пользовательской документации в 2026 году?
Уже сейчас можно начать экспериментировать с комбинацией "скриншот + LLM", чтобы оценить, насколько такой подход сокращает время выпуска документации. Те, кто освоят эту связку в 2026, через год будут тратить на рутину в разы меньше времени.
Дополнительные материалы
- Playwright Documentation — официальное руководство по автоматизации браузера.
- Sharp API Reference — документация по обработке изображений и композитингу.
- Handlebars Guide — основы шаблонизации для настройки выходного Markdown.
- GitHub Actions Workflow Syntax — полный справочник по YAML-конфигурациям.
- Исходный проект ai-docs-agent — оригинальная версия агента с примерами расширений.